Radio Applications of Deep Learning Noise Suppression and Speech Enhancement Part 1: Current Deep Learning Apps
NVIDA
My initial contact with deep learning noise reduction was the NVIDA RTX Voice beta. It is meant to work with the new NVIDA RTX graphics cards but works with some earlier ones, specifically the GTX 1060 in my machine. The installer needs to be hacked for non-RTX cards but needs the latest NVIDA drivers.The RTX Voice beta seems a very early release with very little documentation, other than how to install and use it. It seems to be part of the RTX Broadcast Engine but not documented.
https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
https://devblogs.nvidia.com/nvidia-real-time-noise-suppression-deep-learning/
RTX Broadcast Engine: GPU-accelerated SDKs that deliver AI-powered content creation features
https://developer.nvidia.com/rtx-broadcast-engine
Krisp-2Hz
Started as 2Hz then became Krisp. Much that was promised by 2Hz doesn't seem to be available through Krisp, such as stand-alone (vs cloud) and API. They may be available but I haven't been able to find them.https://krisp.ai/ Mute background noise in any communication app
https://devblogs.nvidia.com/nvidia-real-time-noise-suppression-deep-learning/#disqus_thread By 2Hz
https://software.intel.com/en-us/articles/clean-up-noise-pollution-with-krisp-by-2hz
https://krisp.ai/blog/krisp-with-new-10gen-intel-chipset/
https://sigport.org/sites/default/files/docs/PosterFinal.pdf Intel 10th Gen GNA (Gaussian Network Accelerator)
https://krisp.ai/blog/6-noise-measuring-apps/
https://krisp.ai/blog/noise-cancelling-software-for-pc-to-remove-background-noise/
BabbleLabs
BabbleLabs Clear Cloud™ Speech Enhancement Technology"The Clear Cloud API allows developers to utilize best in class speech enhancement for common format video and audio. The easily integrated API is designed for a wide range of application development — VoIP, broadcasting and live streaming, interactive voice recording (IVR), digital voicemail, automatic speech recognizers, games, and entertainment."
https://babblelabs.com/products/
https://babblelabs.com/products/clear-cloud/ API
RNNoise
Using Deep Learning for Noise Suppression. Low CPU load, runs on a Raspberry Pi. Does not seem to be pursued any further than the 2017 paper.https://people.xiph.org/~jm/demo/rnnoise/
https://hacks.mozilla.org/2017/09/rnnoise-deep-learning-noise-suppression/
https://jmvalin.ca/index.html
Microsoft Teams
Noise suppressionhttps://techcommunity.microsoft.com/t5/microsoft-teams-blog/what-s-new-in-microsoft-teams-3rd-anniversary-edition/ba-p/1234871
https://www.microsoft.com/en-us/research/project/speech-enhancement/
Dr. Yong XU
https://sites.google.com/view/xuyong/homehttps://github.com/yongxuUSTC Github home and directory
https://github.com/yongxuUSTC/DNN-for-speech-enhancement
Other noise-cancelling software via Krisp blog post
https://krisp.ai/blog/noise-cancelling-software-for-pc-to-remove-background-noise/Books on speech enhancement
P. C. Loizou, "Speech Enhancement: Theory and Practice". Boca Raton, FL, USA: CRC, 2013.J. Benesty, S. Makino, and J. D. Chen, "Speech Enhancement". New York, NY, USA: Springer, 2005.
"Audio source separation and speech enhancement " Emmanuel Vincent, Tuomas Virtanen, Sharon Gannot 2018
Github software
Real-time GCC-NMF Blind Speech Separation and Enhancement
https://github.com/seanwood/gcc-nmf
Speech enhancement method using deep learning approach for hearing-impaired listeners
https://journals.sagepub.com/doi/full/10.1177/1460458219893850
Radio implications for speech enhancement and noise suppression
Miss-tuned SSB
Miss-tuning creates problems for noise suppression as the demodulated voice frequencies are different from what the DNN has learned. For a human operator, up to about 50 Hz error can be tolerated. However, TRX can drift or simply not be calibrated accurately.Humans can tune the signal by ear to reduce the error but this is progressively more difficult for a noise signal; the skill of the operator. With limited experimentation, the NVIDA adjustable noise suppression can be used, a little while tuning and more once tuned. This is the simplest approach.
It is probably possible for the DNN to recognise voice with a frequency error of up to 50 Hz, maybe more. This may not be too difficult if the DNN needs to learn typical radio noises rather than the environmental noise it has been trained with. The frequency error, DNN noise suppression would seem to aid tuning.
Other TX modes could be used to help or automate tuning. SSB, as used by amateur radio dates back to 1960s technology. Other modes were developed but not widely used for automatic tuning. One is SSB-reduced carrier A3A with the carrier 16 db below PEP. With SDRs, it is possible to generate and demodulate A3A yet it still can be demodulated with ordinary SSB RX. Given amateurs' reluctance to change, it is unlikely to be widely adopted, but could be of interest to some.
Single-sideband reduced carrier. A3A signals are defined by the CCIR as a single-sideband emission in which the carrier power is 16 dB below PEP.
A COMPARISON OF AM AND VARIOUS SSB MODELS ON 2182 KHZ Kenneth Richard Mass
https://core.ac.uk/download/pdf/36714015.pdf Discusses practical issues of AM, SSB and reduced carriers SSB for offshore boating. 1975
Can DNN noise suppression help CW or low data rate voice and data digital modes?
Probably getting ahead of the field, but could DNN noise suppression aid CW or even HF digital modes (voice and data)? In its current form, DNN would treat the tones as noise and reduce them, but presumably, it is possible for DNN to learn the tones as valid. DNN can be used instead of DSP or in conjunction with it.CW
CW would seem the easiest, a relatively low data rate and just long or short tones. Again, tuning is a problem but could be overcome with auto-tuning to standard tones, such as 600 Hz(??). I don't know how the automatic CW decoding plugins work, but they would need to do something similar. Further, as well as de-noising CW for an operator, it would seem that DNN may be able to aid de-coding to text as well. The single frequency channel may be too narrow for current speech DNN and require recoding to suit.
Low data rate digital voice modes
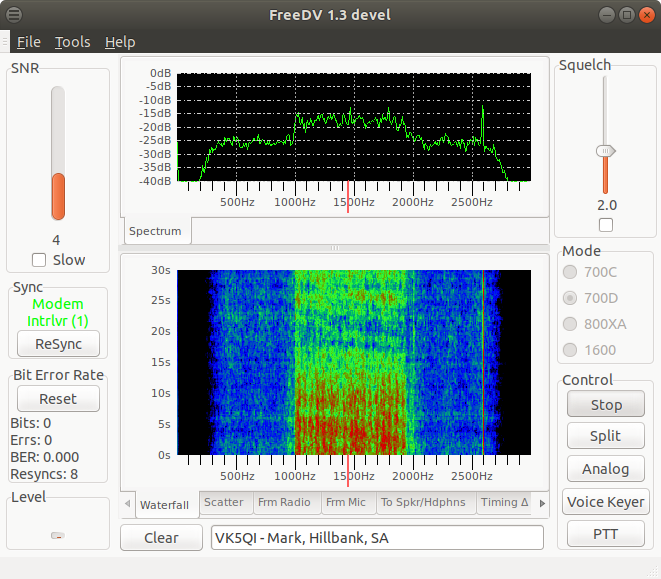
Low data rate digital voice modes such as FreeDV may be aided by DNN noise suppression with appropriate learning. From the literature on speech enhancement, both frequency and phase are considered. The FreeDV waveform consists of 14 differential quadrature phase-shift keying (DQPSK) carriers with 75-Hz spacing between centres and a total bandwidth of 1.125 kHz and a data rate of 1450 bit/s. As such, the waveform may be sufficiently similar to voice to use the current DNN but with appropriate learning.
https://freedv.org/freedv-specification/
Low data rate data modes
Similar to low data rate digital voice modes, low-speed data modes such as FT8 may benefit from the combination of DNN with the sophisticated DSP that they currently use. Again, the DNN would need to be incorporated into the plugin necessitating a fair bit of coding on top of the learning. The very narrow channel of FT8 may be a problem. Current speech DNN divides speech into channels but may need rewriting for this application.

Comments
Post a Comment